hibernate主要封装java里面jdbc这部分,是jdbc代码的轻量级的对象封装,使用hibernate有很多好处:
1、降低了代码的耦合性,程序员只需要专注业务代码即可
2、换了数据库只需要改动配置文件即可
3、大大提高程序员的开发效率
4、支持分布式架构
hibernate核心思想是ORM(object relation mapping),官方推荐先写domain层,再写配置文件,最后生成数据库,但是实际上都是先设计好数据库,然后写配置文件,最后再写domain层,这里也是按照实际顺序配的
数据库代码(使用的是mysql数据库,以employee为例):
1
2
3
4
5
6
7
| CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) NOT NULL,
`email` varchar(64) NOT NULL,
`hiredate` date NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
|
我们在这张表里面设计了4列,分别是主键id(int类型),name(varchar类型),email(varchar类型),hiredate(date类型),那么我们的domain类的结构也要设计成一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| package com.ganmy.doman;
public class Employee implements java.io.Serializable{
private static final long serialVersionUID = 1L;
private Integer id;
private String name;
private String email;
private java.util.Date hiredate;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public java.util.Date getHiredate() {
return hiredate;
}
public void setHiredate(java.util.Date hiredate) {
this.hiredate = hiredate;
}
|
接下来是hibernate与数据库的连接配置文件hibernate.cfg.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| <?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">
<![CDATA[jdbc:mysql://localhost:3306/users?useUnicode=true&characterEncoding=utf8]]>
</property>
<property name="connection.username">root</property>
<property name="connection.password">root</property>
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="show_sql">true</property>
<property name="format_sql">true</property>
<mapping resource="com/ganmy/doman/Employee.hbm.xml"/>
</session-factory>
</hibernate-configuration>
|
然后是对象关系映射文件,mvc模型的设计理念是一张表对应一个类,表里面一行对应一个对象,hibernate也是这样设计的,实现对象与数据库表的映射关系的核心文件是类名.hbm.xml,一般这个类名和表名一样,只是首字母大写,我们的表名是employee,那么对应的文件就是Employee.hbm.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| <?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.ganmy.doman">
<class name="Employee" table="employee">
<id name="id" column="id" type="java.lang.Integer">
<generator class="increment"></generator>
</id>
<property name="name" type="java.lang.String">
<column name="name" not-null="false" />
</property>
<property name="email" type="java.lang.String">
<column name="email" not-null="false" />
</property>
<property name="hiredate" type="java.util.Date">
<column name="hiredate" not-null="false" />
</property>
</class>
</hibernate-mapping>
|
最后是我们的调用,主要是main方法的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public static void main(String[] args) {
Configuration configuration = new Configuration().configure();
SessionFactory sessionFactory = configuration.buildSessionFactory();
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
Employee employee = new Employee();
employee.setName("zhangsan");
employee.setEmail("1556254@123.com");
employee.setHiredate(new Date());
session.save(employee);
transaction.commit();
session.clear();
}
|
这里说明一下:
1、sessionFactory是一个重量级的接口,会占用很多内存,我们要保证一个数据库只对应一个sessionFactory
2、session指的是代码和数据库之间的会话,不是我们javaweb里面的session
3、hibernate设计者设计在对表进行增删改操作的时候要使用事务提交,如果不使用事务提交将无法生效,也不报错,下面是具体的优化,由于sessionFactory是一个重量级的接口,会占用很多内存,我们要保证一个数据库只对应一个sessionFactory,使用静态代码块和单例模式来加载sessionFactory的创建,将sessionFactory封装到一个类里面
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| final public class MySessionFactory {
private static SessionFactory sessionFactory=null;
private MySessionFactory(){};
static{
sessionFactory = new Configuration().configure().buildSessionFactory();
}
public static SessionFactory getSessionFactory(){
return sessionFactory;
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public static void main(String[] args) {
updateEmployee_roll();
}
private static void updateEmployee_roll() {
Session session = MySessionFactory.getSessionFactory().openSession();
Transaction ts = null;
try{
ts = session.beginTransaction();
Employee emp=(Employee)session.load(Employee.class, 2);
emp.setName("甘明阳11");
emp.setEmail("123@11");
int i = 9/0;
ts.commit();
session.close();
}catch(Exception e){
if(ts != null){
ts.rollback();
}
throw new RuntimeException(e.getMessage());
}finally{
if(session!=null&&session.isOpen()){
session.close();
}
}
}
|
使用事务模版写最安全,即使报错不会提交到数据库,可以保证数据的完整性,而且能快速定位到错误。
session的获取
session的获取方式有两种,分别是openSession()和getCurrentSession(),特点:
1、openSession()是获取一个新的session
2、getCurrentSession()获取和当前线程绑定的线程,换言之,在同一个线程中,我们获取的session是同一个session,这样可以利于事务的控制
3、如果希望使用getCurrentSession(),需要配置hibernate.cfg.xml,添加:
1
2
| //thread代表session可以和当前线程绑定
<property name="current_session_context_class">thread</property>
|
根据实际应用选择使用那个session,如果在同一个线程中,保证要使用同一个session就使用getCurrentSession(),如果在一个线程中要使用不同的session就使用openSession()
4、通过getCurrentSession()获取的session在事务提交以后会自动关闭,通过openSession()获取的session必须手动关闭
5、如果是通过getCurrentSession()获取的session在进行查询的时候也要以事务的方式提交,而且在commit以后,对象获取属性会报错could not initialize proxy - no Session,要在commit之前获取属性
全局事务和本地事务
假如我们使用的数据库只有一个,那么控制这个数据库的事务就是本地事务,假如我们连接多个数据库,比如银行的转账系统,从工行转账到农行,那么控制这个跨数据库的事务就被成为全局事务(jta),全局事务的价值更高
session获取对象的两种方法
session获取对象的两种方法分别是get()和load(),他们的区别是:
1、查询没有的数据返回不同,例如一个表只有10行数据,我们去第100行的数据,那么使用get()会返回null,而使用load()会报错ObjectNotFoundExpcetion
2、使用get查询数据会先到session缓存去查然后去二级缓存去查,如果没有立即向数据库发出sql语句,查询到了不会发sql语句。
使用load()去查询,也是先到session缓存去查然后去二级缓存去查,如果没有找到就返回一个代理对象,不会立即向数据库去查,等到后面使用这个代理对象操作的时候,才到DB中去查,这个现象我们称为lazy load(懒加载),如果用户后来真的要用到这个对象,那么load()回到数据库去查,然后把查询的的结果存放到二级缓存里面,下一次再用这个sql语句去查询还是按照一级缓存、二级缓存的顺序去找,这个时候二级缓存已经有这个数据就不会到数据库去查了,如果二级缓存的命中率很高就会将这个结果放到一级缓存里面。
3、通过修改配置文件可以取消懒加载,在*.hbm.xml里面的class标签添加一个属性laze=”false”就行了
4、如果确定数据库一定有这个对象就使用load(),效率比较高,如果不确定就使用get(),防止报错
一级缓存和二级缓存
一级缓存就是sessionfactory的缓存,又叫session级缓存,二级缓存是介于文件和内存之间的缓存,一级缓存不需要配置就可以用,二级缓存需要配置启用才能用,缓存的机制可以减少对数据库的频繁访问,由于hibernate的缓存机制实现的很好,使用hibernate可以优化对数据库查询的次数
线程局部变量模式
一般我们的变量范围是一个函数域,但是其实变量是可以和一个线程绑定的,这就是线程局部变量模式,还是以session为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| package com.ganmy.util;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtil {
private static SessionFactory sessionFactory = null;
private static ThreadLocal<Session> threadLocal = new ThreadLocal<Session>();
private HibernateUtil(){};
static{
sessionFactory = new Configuration().configure().buildSessionFactory();
}
public static Session OpenSession(){
return sessionFactory.openSession();
}
public static Session getCurrentSession(){
Session session = threadLocal.get();
if(session == null){
session = sessionFactory.openSession();
threadLocal.set(session);
}
return session;
}
}
|
将session放到本地线程threadLocal里面,以后可以直接从threadLocal获取,这样写就不需要配置thread了。
Query接口
在hibernate里面的查询使用hql语句,使用hibernate我们只需要写hql语句查询,不需要分数据库,因为hibernate会根据不同的数据库将hql语句翻译成对应的sql语句,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public static void main(String[] args) {
Session session = HibernateUtil.getCurrentSession();
Transaction ts = null;
try{
ts = session.beginTransaction();
Query query = session.createQuery("from Employee where id = 100");
List<Employee> list = query.list();
for(Employee e:list){
System.out.println(e.getName()+e.getEmail());
}
}catch(Exception e){
if(ts != null){
ts.rollback();
}
}
}
|
使用逆向工程生成配置文件
一、使用数据库浏览器连接数据库
1、创建数据库表
2、创建java项目
3、通过myeclipse的数据库浏览器连接到mysql数据库
打开数据库浏览器 ->windows -> open persective -> Myeclipse Database Explorer->在DB Brower点击右键->
选择new,按照如图所示填写
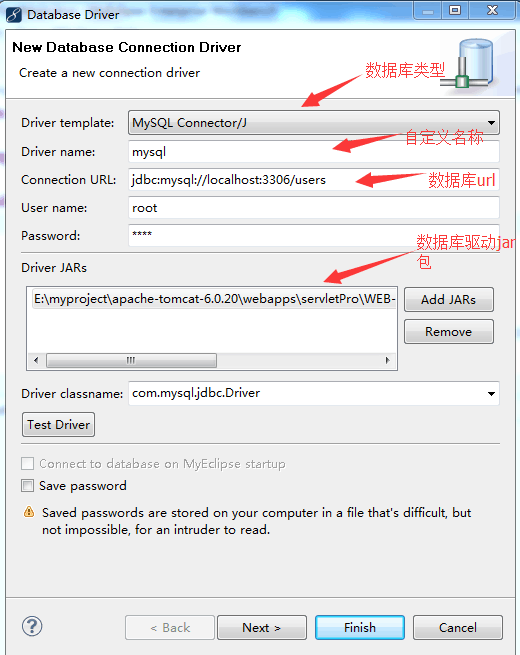
点击Test Driver弹框success表示连接成功
然后在打开右边的项目,找到table,右键,Edit data就可以了
注意mysql5.6的版本不能用5.0的jar包连接,会报错,要用支持5.6的jar包需要使用5.1.25版本的驱动,而且貌似数据库浏览器好像有缓存的样子,我换了一个高版本的jar包还是报错,然后我以为是jar版本不对,陆陆续续在网上找了很多版本的jar包,但是无一例外全部报错,我真的被搞的头都大了,搞了一天没找到原因,后来我思路一转,是不是数据库的问题不是jar包的问题呢,连接我云服务器的mysql,结果可以,然后再连接本地的mysql也都可以了,真的是一脸懵逼的解决了问题。
二、引入hibernate开发包
项目右键->myeclipse->add hibernate capabilities,按照如图所示填写
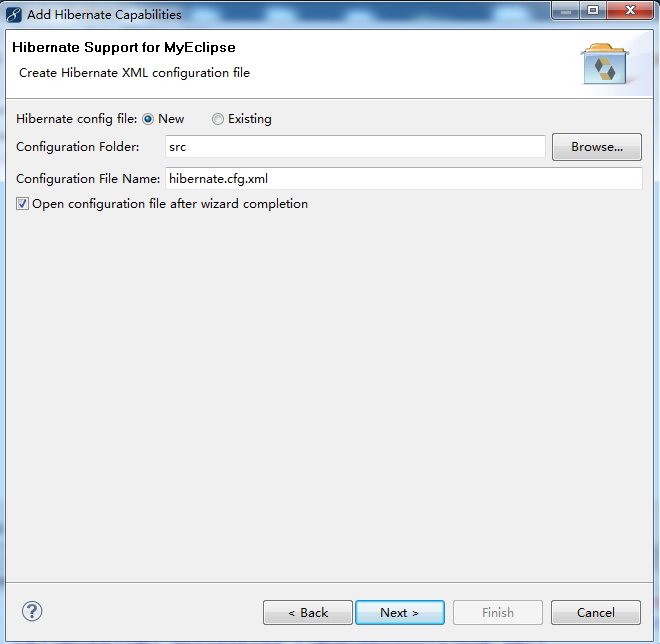
点击Next
点击Next
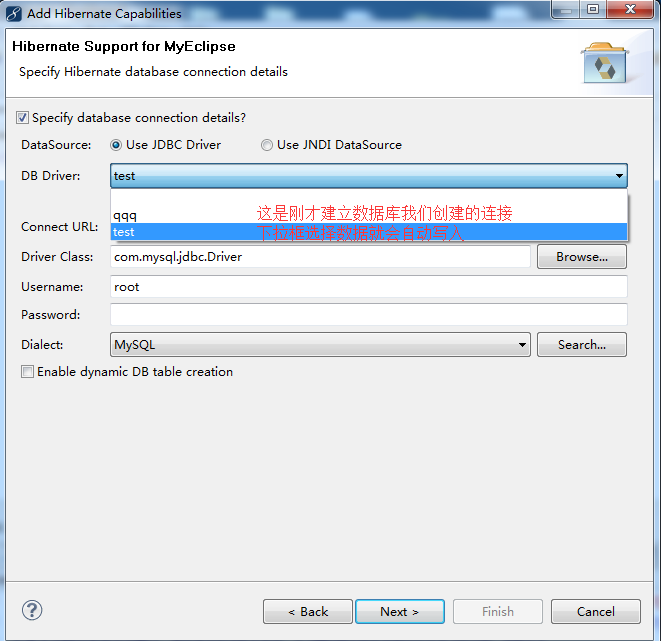
点击Next
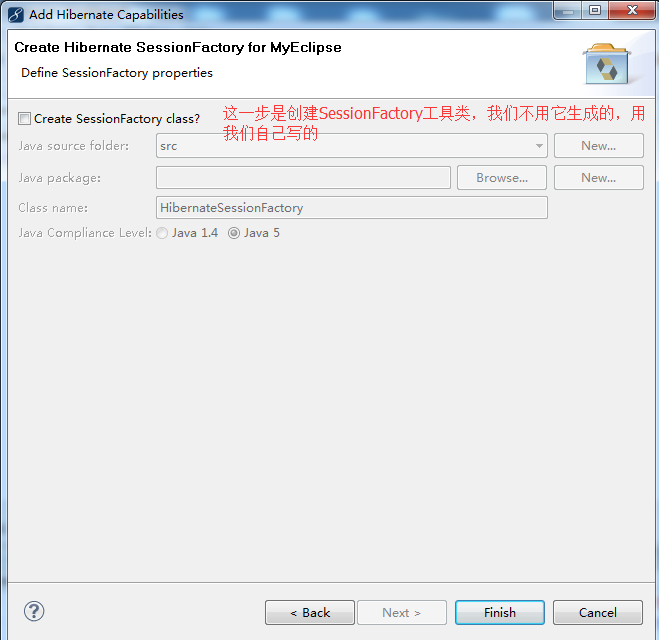
如果希望把hibernate开发包升级,我们可以重新引入包,到文件路径把自动引入的jar包删掉,然后将我们自己的jar包引入
然后我们到数据库浏览器这一边,右键点击表,选择hibernate reverse engineering
点击browse选择包,将domian对象所在的包引入,下一步
、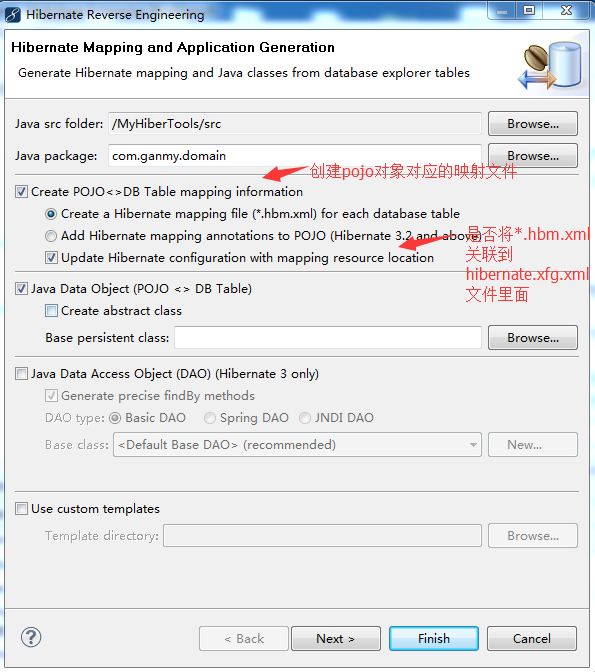
然后下一步下一步点finally就可以了
最后:感觉hibernate真的大大提高了程序员的效率,不用写jdbc代码了,是一个值得学习的框架