hibernate里的HQL使用详解
HQL介绍
HQL是Hibernate Query Language的简写,翻译成中文就是hibernate查询语言,是面向对象的查询语句,功能强大,由于实际需求的复杂性,对数据库的操作有很多条件,用原始的get()和load()远远满足不了需求,这个时候hibernate推出了功能强大的HQl语句,hql语句和sql语句不同,hql严格区分大小写,并且支持多态。
hibernate设计者建议数据库所有表都要有主键,而且最好是不要带业务逻辑的主键,原因:
1、很多情况下业务需求有可能改动,那么就面临要修改主键,对这条数据来说修改主键就面临数据不稳定的状态。
2、带有业务逻辑的数据有可能会重复,比如早期的身份证号,由于很多原因,出现了重复的现象。
例如我对查询student表里面所有属性
1 | public static void main(String[] args) { |
这里最主要的语句就是List<Student> list = session.createQuery("from Student").list();这一句,由于在hibernate里面一张表对应一个类,我们的student表对应的类就是Student,hql语句面向对象的,是去查询这个类的属性而不是去查表的属性,直接’from student’就表示查询Student的所有属性,返回一个装满Student对象的集合,然后我们只需要对集合做操作就可以了,可以使用for循环增强也可以使用Iterator迭代器取出数据。两种方式上面都列举出来了。
在jdbc里面一般不要使用select * from 表名,但是这个规定在hibernate里面可以不遵循这个规则,如果遵循这个规则Hibernate的优势体现不出来,hibernate建议我们把整个对象的所有属性都查出来。
如果要查询部分信息,那么只需要将hql语句改动就可以了,例如我只想查询名字和所在系:
改成
1 | List list = session.createQuery("select sname, sdept from Student").list(); |
但是由于我们只是查询一部分数据,不足以构成一个Student,所以不能用Student类的方法来取数据,使用以下方法取出数据
1 | for(int i=0;i<list.size();i++){ |
这是因为数据不足以构成student对象,于是使用数组代替,这个list里面是像数据库一样两列多行数据,我们取出第一行数据,这个数据会放到一个数组里面,由于不知道数据的类型,就使用object对象指带,防止报错。当然,这种情况我们还得自己做二次封装,比较麻烦。不能发挥hibernate关联查询的特点。所以还是建议使用hibernate的所有查询语句,其实浪费的性能不多,因为实际上我们去查询都会带上各自条件,并且会带上分页,其实每一次查询出来的数据量一般不会特别多,我们甚至可以查出关联外键表的数据
1 | List<Student> list = session.createQuery("from Student").list(); |
hibernate真的是完全的面向对象编程
uniqueResult查询
这是hibernate推出的一种查询方法,业务场景是用于查询数据只有一条的情况,因为假如我们使用get()或者load()查询,假如数据量有几百万在查询到的情况下还会接着往下查,uniqueResult查到了不会往下查,例如我们要根据某个id查询
1 | Student s = (Student) session.createQuery("from Student where sid = '20050003'").uniqueResult(); |
如果查到了就返回一个对象,如果是查询全部属性就返回一个Student对象,如果是部分属性就返回一个object[]数组,没有查到会返回null,如果查询结果有多条会抛出异常,用户登录的场景建议使用这种查询
其他用法
过滤重复数据
使用distinct关键字,例如显示所有学生的性别和年龄
1 | List list = session.createQuery("select distinct ssex, sage from Student").list(); |
根据区间查询
使用bewtween…and.. ,例如我想查询年龄在20岁和22岁之间所有学生的性别
1 | List list = session.createQuery("select ssex, sage from Student where sage between 20 and 22").list(); |
使用int和 not in来查询,例如我想查询所有年龄为20岁或者22岁的学生
1 | List<Student> list = (List<Student>) session.createQuery("from Student where sage in (22,20)").list(); |
分组层查询
使用group by来查询,例如我想查询各个系的学生的年龄
1 | List list = (List<Student>) session.createQuery("select sage from Student group by sdept").list(); |
这里由于我查询的只有一个属性,不会返回object[]数组了,可以直接从list里面取出来
如果是查询各个系的平均年龄
1 | List<Object[]> list = session.createQuery("select avg(sage),sdept from Student group by sdept").list(); |
对分组后的数据再次查询
使用having来查询,例如我想显示所有人数大于3的系
1 | List<Object[]> list = session.createQuery("select sdept, count(*) from Student group by sdept having count(*)>3").list(); |
注意在hibernate里面having后面不能跟别名,要跟聚合函数,看了下sql语句,由于hibernate会把count(*)取一个自动的别名,我们取的别名没有生效,这种情况直接用别名去判断就报错找不到这个字段
查询女生人数少于200的系
1 | List<Object[]> list = session.createQuery("select sdept, count(*) from Student where ssex='F' group by sdept having count(*)<200").list(); |
查询学生总分
1 | List<Long> list = session.createQuery("select sum(grade) from Studcourse").list(); |
查询选修11号课程的最高分和最低分
1 | List<Object[]> list = session.createQuery("select 11,max(grade),min(grade) from Studcourse where course.cid = 11").list(); |
显示各科不及格的学生名字,科目和分数
1 | List<Object[]> list = session.createQuery("select student.sname,course.cname,grade from Studcourse where grade < 60").list(); |
这里非常巧妙的用到了hibernate的面向对象思想,通过对象的属性获取,如果单纯使用数据库还是不太好处理的
这里是生成的sql语句,感觉写的挺好的
1 | select |
统计各个科目不及格的学生的数量
1 | List<Object[]> list = session.createQuery("select count(*),course.cname from Studcourse where grade < 60 group by course.cname").list(); |
分页
使用关键函数setFirstResult(index)和setMaxResults(index) 例如:按照学生年龄从小到大取出第一个到第三个学生
1 | List<Student> list = session.createQuery("from Student order by sage asc").setFirstResult(0).setMaxResults(3).list(); |
注意setFirstResult的参数表示数据的下标,setMaxResults的参数表示后面几位,和limit的用法一样
封装成函数
1 | //分页函数 |
调用
1 | public static void main(String[] args) { |
这个分页方法还是非常方便的,不管什么数据库都可以使用,hibenate会转化成相应的sql语句
hibernate参数绑定
使用关键函数,setParameter() ,使用参数绑定的好处:
1、可读性好
2、性能提高
3、防止sql注入漏洞
关于sql注入漏洞,举例说明:
我的数据库表:
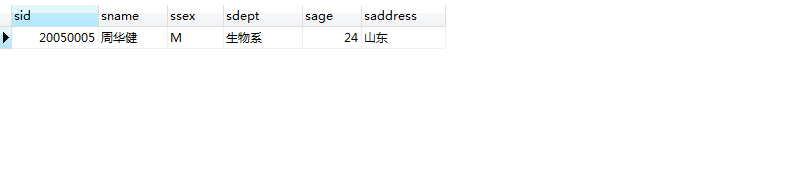
使用sql语句查询
1 | SELECT * from student where sid = 20050005 and sdept='生物系' |
可以查到数据
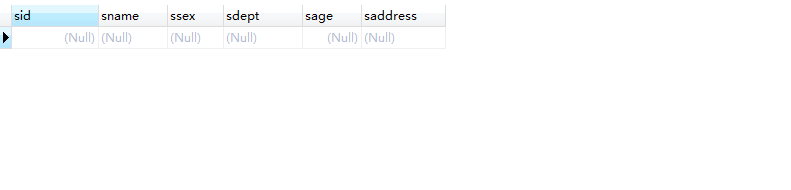
改一下:
1 | SELECT * from student where sid = 20050005 and sdept='生物系111' |
查不到数据
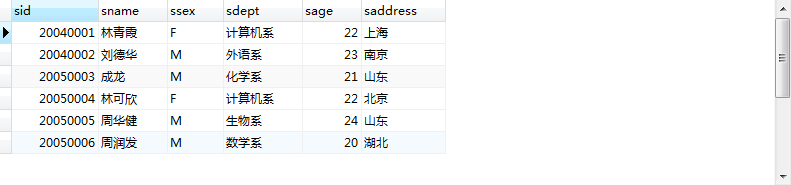
再改一下
1 | SELECT * from student where sid = 20050005 and sdept='生物系111' or 1='1'; |
所有的数据都出来了
实际上这是因为where执行的语句可以返回一个boolean,当这个boolean的值为true的时候,会查出所有数据,当这个boolean的值为false的时候,就什么都查不到,例如我们直接使用true来查,看结果
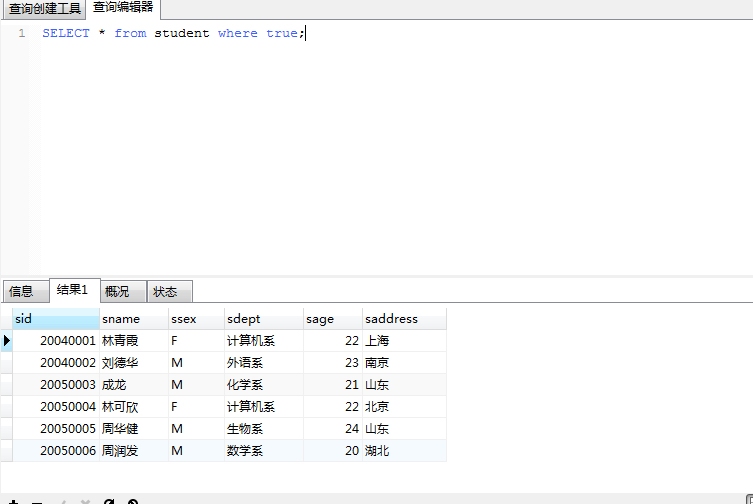
所谓的sql注入漏洞其实就是通过or语句来返回一个true,达到获取用户所有数据的目的
参数绑定有两种形式:
1、使用:字段名
1 | List<Student> list = session.createQuery("from Student where sdept=:a1 and sage>:sage").setString("a1", "计算机系").setString("sage", "2").list(); |
注意 “:” 后面的字符串可以随便取名,但是一般和字段名保持一致,后面的setString不能用位置做第一个参数
2、使用?占位符
1 | List<Student> list = session.createQuery("from Student where sdept=? and sage>?").setString(0, "计算机系").setString(1, "2").list(); |
这样使用?占位符后面的setString才能用位置做第一个参数,然后参数是从0开始编号的
另外query是可以分开写的,不是一定要连起来写
1 | Query query = session.createQuery("from Student where sdept=? and sage>?"); |
由此我们可以引申,使用for循环注入,将方法封装起来
1 | //提供一个统一的查询方法,hql形式,使用?的方式,由于openSession在查询的时候不需要使用事务提交,就不用openSession |
关于静态的使用,代码块本身是可以静态的,但是session要保证每次都是一个新的,不是当前的那个,防止阻塞的问题
关于调用
1 | public static void main(String[] args) { |
将以上代码功能完善,添加分页功能
1 | //提供一个统一的分页查询 |
这个时候main方法调用
1 | public static void main(String[] args) { |
然后是统一的添加方法
1 | public static void excuteAdd(Object obj){ |
统一的修改和删除方法
1 | public static void excuteUpdate(String hql,String[] parameters){ |
使用子查询
例如查询所有选课为21号的学生的信息
有两个方法,一、获取Studcourse对象,根据Studcourse获取Student对象
1 | String hql = "from Studcourse where course.cid=21"; |
这里有一个懒加载的问题,会报错
1 | Exception in thread "main" org.hibernate.LazyInitializationException: could not initialize proxy - no Session |
这是由于我们获取的Student对象是一个代理对象(proxy),由于session已经关闭,到数据库查询会报错
对Student.hbm.xml设置禁用懒加载,添加属性laze=”false”就可以了,但是这种方式会多次连接数据库,for循环有几次就会去数据库查几次,效率很低下
方法二、通过面向对象取出来
1 | String hql = "select student.sname,student.sid from Studcourse where course.cid=21"; |
这种方法的缺点是hql语句过长
critiria使用
critiria是一种更加面向对象的查询,例如查询年龄大于10岁的学生
1 | public static void main(String[] args) { |
使用模糊查询
例如:查出所有成姓学生
1 | String hql = "from Student where sname like ?"; |
创建数据库
如果我们要创建出对应的数据库,需要配置hibernate.cfg.xml,添加配置信息
1 | <property name="hbm2ddl.auto">create</property> |
这个标签里面有四种类型的值:
1、create,当我们的应用程序加载hibernate.cfg.xml的时候(new configuration().config())就会根据映射文件创建出数据库,每次都会创建,如果原先有表会先删掉再创建
在*.hbm.xml里面的class标签设置生成表的数据库名和表名,然后在hibernate.cfg.xml文件里面添加
1 | <property name="hbm2ddl.auto">create</property> |
主要是这种创建方式会删掉原来表中的数据
2、update,如果数据库中没有该表,则创建,如果有该表,则看有没有变化,如果有变化,则更新,反正不会删掉表里面的数据
例如我将映射的表字段sdept改为sdept1,字段最大长度从30改为20,那么在表里面就会生成一个新的字段sdept1,长度为20,原先的sdept字段和里面的数据还是保留
3、create-drop,在显示关闭sessionFactory的时候,会drop数据库的schema,我们调用sessionFactory创建session用完sessionFactory也会关闭,但是不是显示关闭,必须要我们调用sessionFactory.close()方法才行,尽量不要使用create-drop
4、validate,每次添加数据的时候会验证数据库的表结构和hbm的结构是否一致,用的很少
在开发测试的过程中,我们配那个都可以,但是如果上了生产,这个选项最好就删掉,要配置也最好配置update,或者配置一次让数据库表生成,然后还是要删掉
关于domain对象
注意:
1、一定要配置默认的构造方法,用于hibernate反射该对象
2、要配置一个没有业务意义的主键
3、给每个属性提供一个get和set方法,原则上一个属性对应数据库表里面的一个字段,或者对应一个对象,如果domian里面有一个字段,我们没有配置到数据库是没有什么关系的,最多只是这个字段不会生成,但是如果我们配置的字段在domain里面没有,就会报错的,因为这个配置会使用domain的反射机制
4、属性一般是private的访问权限
关于可选项
在*.hbm.xml文件里面,table属性可以不写,如果不写就默认使用配置的对象第一个字母小写生成
type也可以不配置,如果没有写,就会根据domain对象对应的属性
hibernate对象三种状态
在hibernate里面将对象分为三种状态,分别是瞬时(transient)、持久(persistent)、脱管(detached)状态
当一个对象刚被创建还没有处于session的管理之下且在数据库中没有记录的时候,是处于瞬时态的(表示状态不稳定,随时都有可能消失),然后我们调用session.save()保存这个对象的时候,它就变成了持久态了,然后当session关闭后,这个对象就脱离了session的管理,状态就变成了脱管态(也叫游离态)
当处于瞬时态的时候改变数据,是不会反映的数据库中,当处于持久态的时候,只要使用set()就会反映的数据库中,脱管状态如果要修改是不会反映的数据库中,例如以下这个例子:
1 | public static void main(String[] args) { |
完整图解,这里说明一下,使用session的get()、load()、find()、iterate()、etc都会进入持久态,并且不管是openSession还是getCurrentSession(),在commit()后都不是持久态了
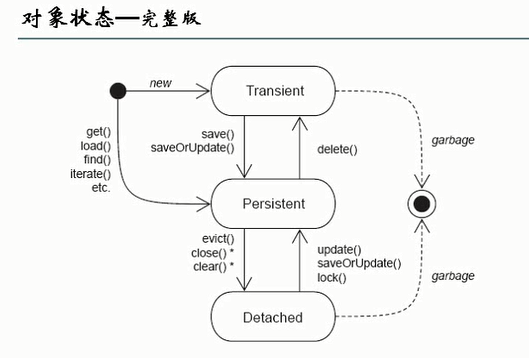
hibernate映射关系
1、one-to-one,例如身份证和人之间的关系
2、one-to-many,例如部门和员工,一个部门可以有多个员工
3、many-to-one,例如员工和部门,多个员工对应一个部门
4、many-to-many,例如学生和老师,一般在编程中要尽量避免这种关系,如果出现了many-to-many,一般转换成两个one-to-many或者many-to-one,这个程序就好控制,同时不会有冗余,例如我们上面的表已经分解了这种关系,hql语句在多表查询有很多优势
在hibernate里面,外键会映射成一个对象